NAOMI - FACIAL EXPRESSION SOFTWARE
by Tobin M. Albanese
PORTFOLIO — SPOTLIGHT 1 Wed Jan 15 2025
Overview. NAOMI (Neural Analysis of Micro-Intent) is an advanced behavioral analytics system designed to detect and interpret micro-expressions — subtle, fleeting facial movements that occur in fractions of a second. These signals, often invisible to casual human observation, can provide important cues about a person’s underlying state such as stress, confidence, or possible deception. NAOMI processes both live and recorded video, tracking facial landmarks at high frequency, and computing temporal deltas across micro-windows of tens of milliseconds. The platform translates this into structured, calibrated outputs that can be reviewed by human analysts, making it a powerful augmentation tool in interviews, intelligence gathering, psychology, user research, and training environments.
Why this matters. Human evaluators are skilled at interpreting broad body language, but the reality is that rapid micro-expressions often occur too quickly for the eye to register, especially under time pressure or distraction. A subtle twitch of an eyebrow, a half-suppressed smile, or a fleeting tightening around the eyes can carry critical meaning — yet they vanish in less than a quarter of a second. NAOMI offers analysts a second layer of observation: a consistent, explainable, high-frequency sensor that runs in parallel with human judgment. Rather than replacing intuition, it strengthens it, ensuring that critical signals are not lost and that evaluators can pause, review, and assess cues in context rather than relying solely on memory or impression.
Objectives. The design of NAOMI is shaped around four central objectives. First, it must deliver true real-time performance, with latencies under 40ms per frame so that overlays remain usable in live scenarios. Second, it must provide explainable outputs — not just black-box classifications, but visible action units, heatmaps, and frame-to-frame deltas that users can understand. Third, it must demonstrate robustness against environmental factors such as poor lighting, angled faces, or partial occlusions like glasses and masks. And fourth, it must maintain full auditability and privacy-conscious design, producing exportable traces for later review while never storing or transmitting sensitive footage unnecessarily. Together, these objectives ensure that NAOMI is not just a research demo, but a deployable and responsible system.
Architecture. NAOMI uses a modular architecture with both edge and server deployment options. At the edge — in-browser or on-device — lightweight models run directly on user hardware, ensuring video never leaves the system. In server deployments, GPU-backed services process streams at scale, enabling batch analytics and long-term archival of inference traces. The end-to-end flow follows a structured pipeline: capture, preprocessing, landmark detection, temporal feature modeling, intent classification, calibration, and finally reporting. Each stage is decoupled, meaning models can be swapped or upgraded independently, giving the system long-term adaptability as methods and hardware evolve.
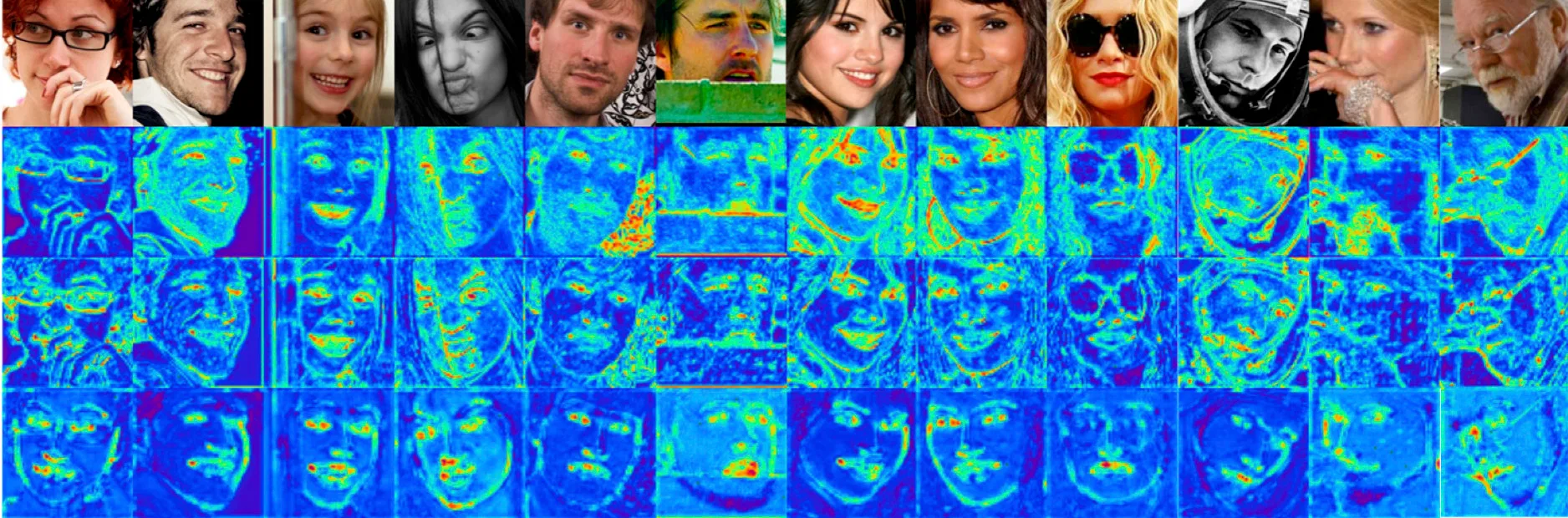
Signal pipeline. At the heart of NAOMI is its signal-processing chain. Each incoming frame undergoes face detection and landmark tracking. These landmarks are compared across micro-windows of 30–80ms, capturing tiny deltas in x/y coordinates that correspond to micro-movements. Temporal models such as BiLSTMs and Temporal CNNs ingest these sequences, smoothing noise, interpolating across small gaps, and handling jitter or occlusion. The model outputs intent predictions, which are then calibrated before being surfaced to the analyst. This pipeline is engineered to balance sensitivity with stability, flagging meaningful signals while suppressing irrelevant motion.
Features. NAOMI’s outputs go far beyond a single probability score. Analysts can access normalized 68- or 106-point landmark maps, per-landmark micro-deltas over short windows, localized action unit activations derived from the Facial Action Coding System, and stabilized overlays produced via optical-flow tracking. Heatmaps highlight regions of the face most associated with detected intent, while frame-level charts show how probabilities rise and fall over time. These multi-layered features ensure that signals remain interpretable and actionable, rather than being hidden inside an opaque classifier.
Modeling & training. The NAOMI models are trained through transfer learning on expression recognition corpora, then fine-tuned with domain-specific adaptations. Datasets are curated with an emphasis on annotation quality: multiple human raters label the same footage, disagreements are adjudicated, and only consensus examples make it into training sets. Probability calibration methods like Platt scaling and temperature scaling ensure outputs reflect real likelihoods rather than overconfident guesses. The training process is not just about maximizing accuracy — it is about producing models whose outputs can be trusted in sensitive human-facing contexts.
Data & labeling. High-quality data underpins NAOMI’s reliability. The system draws from a combination of public corpora, in-house datasets, and synthetic augmentations that simulate different poses, lighting conditions, and occlusions. Each dataset is version-controlled with tools like DVC, enabling traceability of labels and models across iterations. Double-labeling with adjudication ensures inter-rater reliability, reducing noise and bias in the data. By maintaining meticulous provenance of all training material, NAOMI ensures both reproducibility and accountability in its evolution.
Evaluation. NAOMI’s performance is validated through comprehensive benchmarks. On RTX-class GPUs, it achieves frame latencies of 25–38ms, enabling real-time overlays. On modern laptops running edge deployments, it sustains 12–18fps with acceptable accuracy. Robustness testing demonstrates reliable performance up to ±15° yaw/pitch rotation before significant drift. Calibration results show Expected Calibration Error under 0.06 after scaling, meaning probabilities align closely with true likelihoods. These metrics confirm that NAOMI is not only fast, but also trustworthy across varied conditions.
Interface. The analyst interface is designed to make complex signals usable in real-world workflows. In live mode, overlays highlight landmarks, heatmaps, and intent scores directly on the video feed. Analysts can scrub back through footage, adjust playback speed, and inspect frame-level probability charts. Batch mode supports uploads of large video sets with automated summary reports. Adjustable sampling rates let users tune the balance between performance and fidelity. The goal is not just to present data, but to present it in a way that supports fast comprehension and confident decision-making.
API. NAOMI exposes its functionality through a developer-friendly API that delivers structured, machine-readable outputs. Responses include frame indices, raw landmark coordinates, action unit activations, micro-delta RMS values, calibrated intent scores, and precise timestamps. This allows integration into larger systems — from training simulators to research dashboards — without requiring analysts to parse visualizations. By being transparent and consistent, the API ensures NAOMI can plug into diverse ecosystems smoothly.
Deployment. Flexibility in deployment is a core design feature. NAOMI can run entirely on-device for privacy-sensitive use cases, leveraging WebAssembly and WebGL for inference in browsers or desktop applications. In server mode, GPU workers scale elastically via container orchestration, with gRPC/REST endpoints serving multiple clients. Traces and outputs are stored securely in object storage, while CI/CD pipelines automate build and deployment across environments. This versatility allows NAOMI to be deployed in secure labs, enterprise servers, or distributed field environments with equal ease.
Security & privacy. NAOMI was designed with security and privacy as first-class priorities. Role-based access controls determine who can access data and outputs. Encryption protects information at rest and in transit, while retention policies allow organizations to automatically expire sensitive records. Analysts can export anonymized inference traces without exposing raw video. An on-device-only mode is available for the highest-security environments, ensuring no data ever leaves the analyst’s machine. This safeguards trust and compliance in contexts where data protection is essential.
Limitations. Like any AI system, NAOMI has known boundaries. Extreme occlusions such as masks, scarves, or sunglasses reduce accuracy. Cultural and individual differences in expression mean thresholds must be tuned carefully for context. The system is best viewed as an indicator, not a verdict: it surfaces additional cues for human evaluators but is never intended to provide definitive judgments about truth or intent. Being transparent about these limitations is central to NAOMI’s design and ethical positioning.
Ethics. Ethical safeguards are embedded into NAOMI’s deployment philosophy. The system is always human-in-the-loop, requiring explicit consent and documented limits of use. Error rates are disclosed openly rather than hidden, preventing overconfidence. Red-team reviews simulate misuse cases — such as coercive interrogation or surveillance overreach — to identify risks and build mitigations. By prioritizing transparency, consent, and accountability, NAOMI ensures that powerful technology is applied responsibly.
Roadmap. NAOMI’s future development roadmap extends beyond facial micro-expression analysis. Planned milestones include multimodal fusion with audio prosody and keystroke dynamics, enabling richer behavioral insights. Advances in self-supervised pretraining will improve robustness in low-light conditions, while distilled transformer models will bring higher accuracy to lightweight edge deployments. Collaborative analyst note-taking will generate weak labels that feed back into continual learning pipelines. These roadmap items point toward NAOMI evolving into a comprehensive, multimodal human-behavior analytics platform.
Stack. NAOMI is built on a stack of proven technologies and modern ML frameworks. PyTorch provides the foundation for model training and inference, with ONNX enabling optimized, portable runtime execution. OpenCV and MediaPipe power real-time video analysis and landmark tracking. FastAPI and gRPC provide efficient APIs, while React and D3.js render intuitive analyst interfaces. Deployment pipelines use Docker for containerization and Terraform for infrastructure as code, with CI/CD automating continuous delivery. This combination makes NAOMI adaptable, developer-friendly, and production-ready.